My deployment setup (Part 2)
The details of the system architecture of this website
This is a second of two posts in a series of “My deployment setup” posts. You can find the other one here.
The last blog post ended with an infrastructure support for HTTP requests to arrive at my loaned cloud computer. Those requests should be responded to, though, and this is the topic of this post.
Software support
My first deployment used “raw” NGINX. “Raw” here means not using any containerization technologies such as Docker. It was mostly apt install nginx followed by systemctl start nginx.service. The hardest part was writing a .conf file because it was the first time in my life so I had to learn all about NGINX configuration from scratch.
However, this deployment, while working (almost) flawlessly, had one major weakness: it is hard to serve multiple sites from a server in this way. If the sites are static, I should write more .conf files which are all same for the most part (something which can be automated). If the sites are somewhat dynamic, like this blog, this means I should be forwarding the request to another server process, with all the necessary headers etc. Also, nothing was containerized which meant any change in an environment, such as a package update or environment variable change, could result with the deployment failing.
I knew I wanted to deploy multiple containerized sites from the same machine so an archtectural change was inevitable.
Reverse proxy
My requirements were as follows:
- I wanted to deploy multiple sites from the same machine. This meant multiple DNS A-records should point to the same IP address, which is trivial, however there should be a software support for correct dispatching
- I also wanted all the sites to be containerized because it’s easier to update the sites this way, and also the containers are all isolated by design.
- Requirement #2 somewhat implies the dispatch software should also be in a container, as it’s easier for two containers to communicate with each other than a container and a process.
- Ideally, the software dispatch support should be “config, run, and leave it alone”. There should be minimum overhead for every new site to be deployed.
- My final requirement was that it’s possible to collect some metrics (the number of requests in a day for a particular site, status codes etc).
All of these problems are solved by putting a piece of software in front of every site, the so-called reverse proxy.1 I actually contemplated writing my own, thinking “surely it can’t be that difficult”. Luckily, I stumbled upon a piece of software which mstches all the requirements above and much more (and a lot better than I would have). It’s called Traefik.
Traefik
The plan is to put all my sites in a Docker container and to connect them to the Traefik container which will then make them available to the entirety of the Internet.
But, how does the Traefik knows how to forward the correct requests? Do I need to update Traefik for every new container?
Fortunately, no, because that would defeat the purpose. Traefik is configured once at the start and then it autodiscovers the services and the services are responsible for the correct configuration (which is minimal). This means publishing a new site requires only the container and several container labels Traefik reads for the configuration generation. Marvellous.
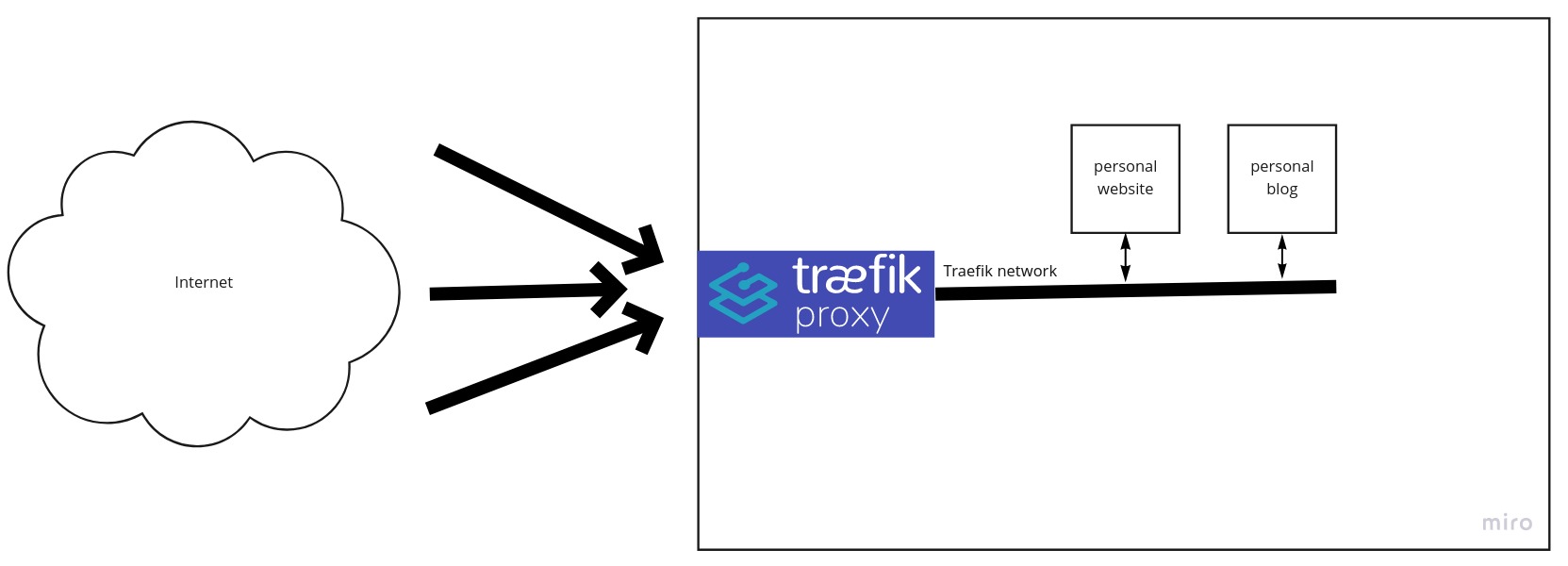
As for the Traefik’s configuration, it’s really minimal: most of the lines go to the SSL certificate provider configuration2 and Prometheus configuration.
Monitoring
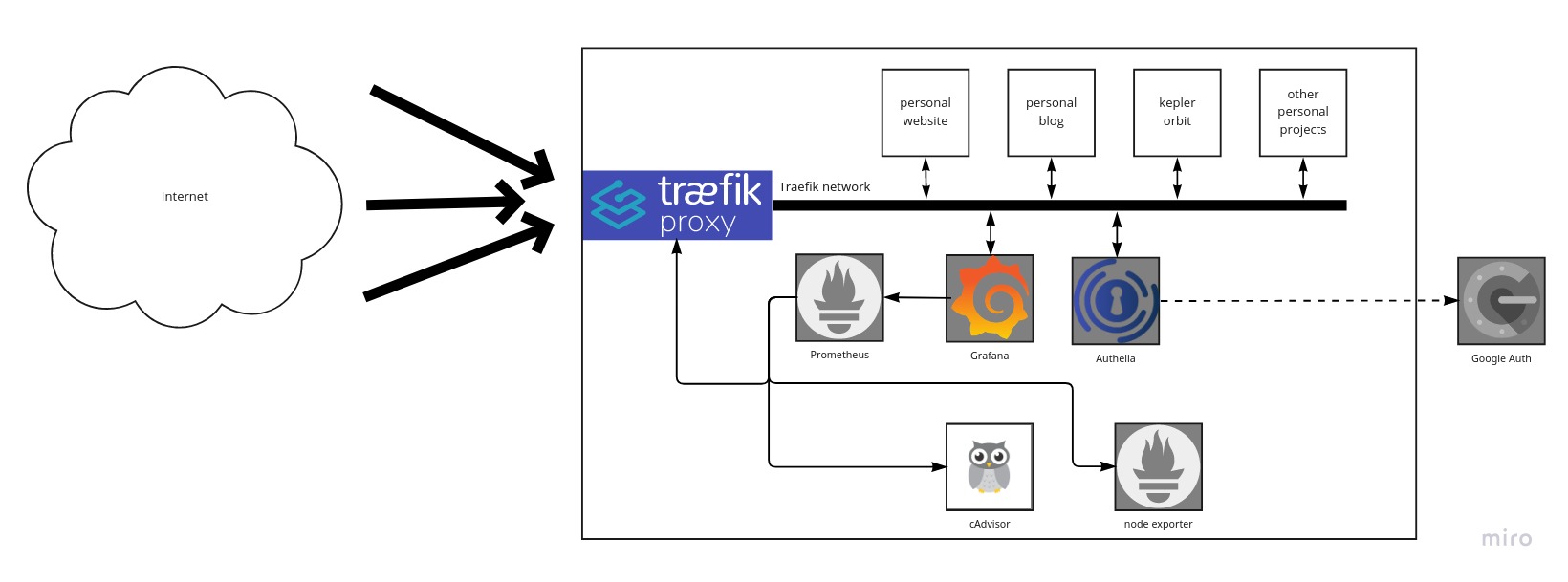
I monitor my deployments with Grafana and Prometheus, which are also Docker containers.
- Prometheus collects the metrics about the sites deployed from Traefik itself (RPS, latencies, IP adresses, status codes etc)
- It collects the metrics about the performance of the site containers, such as RAM usage, CPU usage etc from cAdvisor container
- Prometheus collects the metrics about my cloud computer from a node_exporter container
- Grafana then asks Prometheus for the metrics and shows them in a graphical way.
There is a secret middle step here: these graphs aren’t publicly available to anyone but me. To ensure that, I had to setup an authentication middlestep using Authelia, which asks for the username and password3 and then asks for a 2nd factor authentication with Google Authenticator.4.
The full architecture is as shown in Figure 2:
Final thoughts
In retrospect, my deployment turned out to be more complex than I imagined when I started my architecture redesign. I hadn’t anticipated this as some of requirements changed over time, but luckily, my architecture supported those changes. This taught me what good software architecture should be: it does not only solve your problems now, it also solves your problems later on. And it all started with containerization.
If you wish to know more about my deployment or have any questions or comments, leave them below!
-
Why is it called a reverse proxy instead of a normal (or forward) proxy? Forward proxy acts on behalf on the user/client side of the connection, while reverse proxy acts on the server side. Forward proxy collects requests from multiple clients and then dispatches the responses to correct clients. Reverse proxy dispatches the requests and forwards the responses. ↩
-
Traefik allows you to encrypt your sites with Let’s Encrypt, offering HTTPS out-of-the-box. It also automatically renewes the SSL certificates when they expire, meaning I get to serve my sites with HTTPS and spend roughly 0hrs per year dealing with it
 ↩
↩ -
It’s not
admin:admin↩ -
I’m usually not that self conscious. ↩
Back to main page